
멈추지 않고 끈질기게
[C#] 큐(Queue)와 스택(Stack) 본문
※ 해당 포스팅은 개인의 공부 정리용 글입니다. 틀린 내용이 있다면 추후 수정될 수 있습니다.
※ 해당 포스팅은 .Net 5.0 버전을 기준으로 작성되었습니다.
이번 포스팅에서는 인덱스를 포함하지 않는 자료구조인 큐(Queue)와 스택(Stack)에 대해 알아보겠습니다.
1.큐와 스택의 특징
큐와 스택은 배열이나 리스트와 달리 인덱스를 통해 원소에 접근할 수 없습니다. 리스트처럼 데이터를 하나하나 추가할 수 있지만, 큐는 가장 먼저 넣었던 원소에만, 스택은 가장 마지막에 넣었던 원소에만 접근, 추출할 수 있습니다. 이런 특징을 가리켜 큐를 FIFO(First Input, First Output), 스택을 FILO(First Input, Last Output) 자료구조라 합니다.
그림으로 도식화하면 다음과 같습니다.
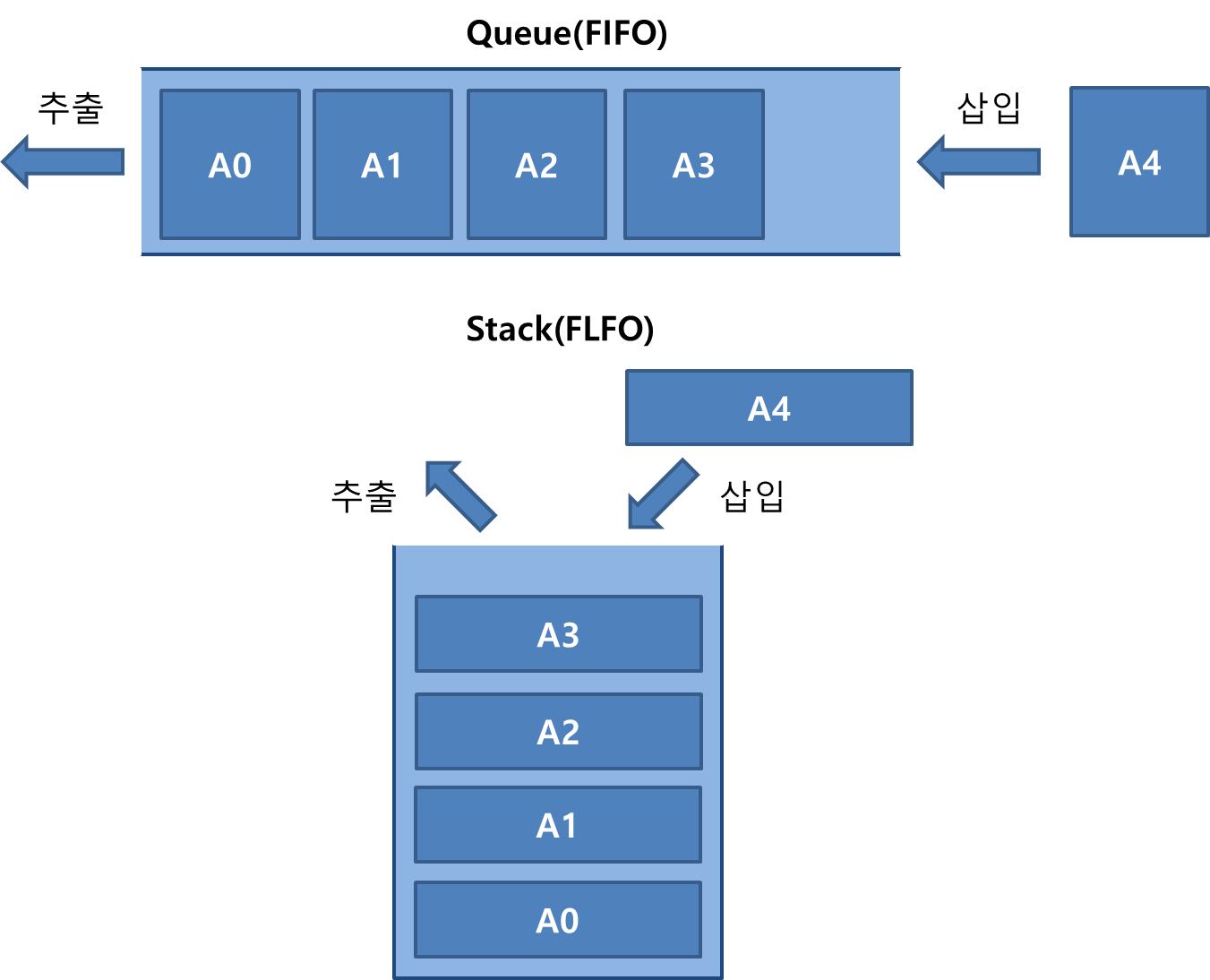
삽입하는 순서가 A0, A1, A2... 순이라면 큐는 가장 먼저 넣은 A0에만 접근할 수 있고, A0을 제거하고 나면 A1, A2, ... 순서로 접근할 수 있습니다. 스택은 반대로 가장 마지막에 넣은 A3에만 접근할 수 있고, A3를 제거하고 나면 A2, A1, ... 순서로 접근할 수 있습니다.
2. 큐와 스택의 선언 및 초기화
큐와 스택은 System.Collections.Generic 네임스페이스에 정의되어 있으며, 다음과 같이 선언 및 초기화 할 수 있습니다.
//선언 후 초기화
Queue<int> que1;
que1 = new Queue<int>();
//선언과 동시에 초기화
Queue<long> que2 = new Queue<long>();
//IEnumerable을 이용한 초기화
float[] arr1 = new float[5];
Queue<float> que3 = new Queue<float>(arr1);
//IEnumerable을 이용한 초기화2
Queue<string> que4 = new Queue<string>(new List<string> { "abc", "def" });
//선언 후 초기화
Stack<int> stk1;
stk1 = new Stack<int>();
//선언과 동시에 초기화
Stack<long> stk2 = new Stack<long>();
//IEnumerable을 이용한 초기화
float[] arr2 = new float[5];
Stack<float> stk3 = new Stack<float>(arr2);
//IEnumerable을 이용한 초기화2
Stack<string> stk4 = new Stack<string>(new List<string> { "ghi", "jkl" });선언 및 초기화에 있어서 큐와 스택간의 차이는 거의 없으며, 둘 다 IEnumerable<T> 타입을 매개변수로 받는 생성자를 가지고 있어 배열이나 리스트를 통한 초기화도 가능합니다.
2. 큐와 스택의 속성
큐와 스택에서 확인할 수 있는 속성 값은 Count 하나밖에 없습니다.
Queue<int> que = new Queue<int>(new int[] { 1, 2, 3 });
Console.WriteLine($"큐의 원소 갯수: {que.Count}");
Stack<int> stk = new Stack<int>(new int[] { 4, 5, 6, 7, 8, 9 });
Console.WriteLine($"스택의 원소 갯수: {stk.Count}");
Count 값은 현재 큐(스택)에 존재하는 원소의 갯수를 나타냅니다. List의 그것과 동일합니다.
3.큐와 스택 관련 함수
큐에서 사용할 수 있는 함수들은 다음과 같습니다.
//원소 삽입
Queue<int> que1 = new Queue<int>(new int[] { 1, 2, 3, 4 });
PrintElements(que1, "큐의 원소: ");
que1.Enqueue(100);
PrintElements(que1, "큐의 원소: ");
//원소 추출
Console.WriteLine($"큐의 원소 추출: {que1.Dequeue()}");
PrintElements(que1, "큐의 원소: ");
//원소 확인
Console.WriteLine($"큐의 맨 앞 원소: {que1.Peek()}");
PrintElements(que1, "큐의 원소: ");
//초기화
que1.Clear();
PrintElements(que1, "큐의 원소: ");
Console.WriteLine();
//원소 확인, 추출의 다른 방법
Queue<int> que3 = new Queue<int>(new int[] { 5 });
for(int i = 0; i < 2; i++)
{
if (que3.TryPeek(out int pk))
Console.WriteLine($"큐의 맨 앞 원소: {pk}");
else
Console.WriteLine("큐에 원소가 없습니다.");
if (que3.TryDequeue(out int result))
Console.WriteLine($"큐의 원소 추출: {result}");
else
Console.WriteLine("큐에 원소가 없습니다.");
}
Console.WriteLine();
//해당 값 보유 여부
Queue<int> que4 = new Queue<int>(new int[] { 7, 8, 9, 10 });
PrintElements(que4, "큐의 원소: ");
Console.WriteLine($"큐에 5가 있는가? : {que4.Contains(5)}");
Console.WriteLine($"큐에 8이 있는가? : {que4.Contains(8)}");
//Queue -> Array 변환
int[] arr = que1.ToArray();
//capacity를 현재 원소 갯수로 조절
que1.TrimExcess();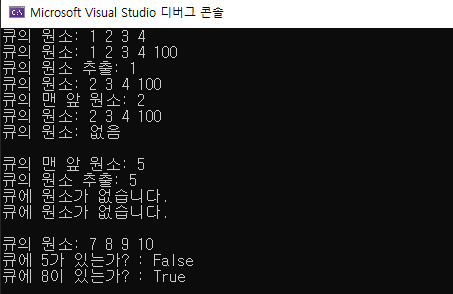
(PrintElements() 개인적으로 foreach 구문을 통해 모든 원소를 출력하도록 작성한 함수입니다.)
Enqueue() 함수는 큐에 맨 뒤에 원소를 추가합니다. 리스트의 Add()와 같은 방식입니다.
Dequeue() 함수는 큐의 맨 앞 원소를 반환하는 동시에 큐에서 해당 원소를 삭제합니다. 상기 코드에서 Dequeue() 함수로
1을 추출한 후 큐의 원소 확인 시 1이 제거된 것을 확인할 수 있습니다.
Peek() 함수는 큐의 맨 앞 원소를 반환합니다. Dequeue()와 달리 해당 원소를 삭제하지는 않습니다. 상기 코드에서 Peek() 함수로 2를 확인한 후에도 큐에 2가 남아있는 것을 확인할 수 있습니다.
Clear() 함수는 큐의 모든 원소를 제거합니다.
TryPeek(), TryDequeue()는 각각 Peek(), Dequeue()와 같은 작업을 수행하나, 해당 작업의 성공 여부를 bool 값으로 반환합니다. 성공 시 결과값은 out 키워드를 통해 받을 수 있습니다. 원소가 없는 빈 큐에 Peek() 이나 Dequeue() 함수 사용 시 InvalidOperationException을 유발하는데, TryPeek()이나 TryDequeue()를 이용하면 좀 더 안전하게 맨 앞 원소를 확인, 추출할 수 있습니다. 상기 코드처럼 해당 함수를 조건식으로 넣어서 사용하면 자연스럽게 예외처리까지 해줄 수 있습니다.
Contains() 함수는 매개변수로 전달한 값이 큐에 존재하는지 여부를 bool 값으로 반환합니다.
ToArray() 함수를 통해 큐를 간단하게 배열로 변환할 수도 있습니다.
TrimExcess() 함수는 해당 큐의 capacity를 현재 원소 갯수에 맞게 조정한다고 되어 있으나, 리스트와 달리 Capacity 속성을 제공하지 않아서 정확히 확인할 수는 없었습니다.
스택에서 사용할 수 있는 함수들도 큐와 대부분 비슷합니다.
//원소 삽입
Stack<int> stk1 = new Stack<int>(new int[] { 1, 2, 3, 4 });
PrintElements(stk1, "스택의 원소: ");
stk1.Push(100);
PrintElements(stk1, "스택의 원소: ");
//원소 추출
Console.WriteLine($"스택의 원소 추출: {stk1.Pop()}");
PrintElements(stk1, "스택의 원소: ");
//원소 확인
Console.WriteLine($"스택의 맨 앞 원소: {stk1.Peek()}");
PrintElements(stk1, "스택의 원소: ");
//초기화
stk1.Clear();
PrintElements(stk1, "스택의 원소: ");
Console.WriteLine();
//원소 확인, 추출의 다른 방법
Stack<int> stk2 = new Stack<int>(new int[] { 5 });
for (int i = 0; i < 2; i++)
{
if (stk2.TryPeek(out int pk))
Console.WriteLine($"스택의 맨 앞 원소: {pk}");
else
Console.WriteLine("스택에 원소가 없습니다.");
if (stk2.TryPop(out int result))
Console.WriteLine($"스택의 원소 추출: {result}");
else
Console.WriteLine("스택에 원소가 없습니다.");
}
Console.WriteLine();
//해당 값 보유 여부
Stack<int> stk3 = new Stack<int>(new int[] { 7, 8, 9, 10 });
PrintElements(stk3, "스택의 원소: ");
Console.WriteLine($"스택에 5가 있는가? : {stk3.Contains(5)}");
Console.WriteLine($"스택에 8이 있는가? : {stk3.Contains(8)}");
//Stack -> Array 변환
int[] arr = stk1.ToArray();
//capacity를 현재 원소 갯수로 조절
stk1.TrimExcess();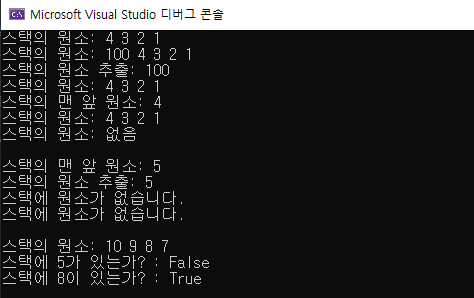
(PrintElements() 개인적으로 foreach 구문을 통해 모든 원소를 출력하도록 작성한 함수인데, 스택의 경우 삽입한 순서와
반대로 나오는 모습을 볼 수 있습니다. 이는 스택이 FILO 자료구조이기 때문입니다.)
Push() 함수는 스택에 원소를 추가하는 함수로, 큐의 Enqueue()와 동일한 기능입니다.
Pop() 함수는 스택에 가장 마지막으로 추가된 원소를 반환하고 제거하는 함수로, 반환 및 제거하는 원소의 기준을 제외하면 큐의 Dequeue()와 동일한 기능입니다.
Peek() 함수는 스택에 가장 마지막으로 추가된 원소를 반환하는 함수로, 반환하는 원소의 기준을 제외하면 큐의 Peek() 함수와 동일합니다.
TryPeek(), TryPop() 함수는 각각 Peek(), Pop() 함수와 같은 작업을 수행하나, 해당 작업의 성공 여부를 bool 값으로 반환합니다. 성공 시 결과값은 out 키워드를 통해 받을 수 있습니다. 큐의 Peek(), Dequeue()와 TryPeek(), TryDequeue()의 관계와 동일하다고 보면 됩니다.
이밖에 Contains(), ToArray(), TriemExess() 함수들은 큐와 동일하므로 생략하겠습니다.
4. 큐와 스택의 장단점
큐와 스택은 배열, 리스트와 달리 인덱스를 통한 접근을 제공하지 않습니다. 따라서 저장한 데이터 중 특정 원소에 접근하는 것은 불가능하며, 오로지 가장 먼저 삽입한 원소부터(큐) 또는 가장 마지막에 삽입한 원소부터(스택) 순차적으로 접근할 수 밖에 없습니다. 또한, 앞서 알아본 배열이나 리스트에 비하면 기능이 상당히 적습니다. 특히 리스트는 큐와 스택의 기능들을 거의 모두 포함합니다. Peek()은 인덱스를 통한 접근으로 대신할 수 있고, Dequeue()나 Pop()은 인덱스를 통해 접근한 뒤 RemoveAt()으로 지우는 식으로 구현할 수 있습니다.
다만 기능이 적다는 것이 꼭 나쁜것만은 아닙니다. 기능과 성능(속도)은 항상 trade-off 관계에 있으니까요.
Stopwatch watch = new Stopwatch();
List<int> list = new List<int>(new int[1000]);
watch.Start();
for(int i = 0; i < 10000; i++)
{
for (int j = 0; j < 10000; j++)
{
list.Add(0);
list.RemoveAt(0);
}
}
watch.Stop();
Console.WriteLine($"리스트 측정 시간: {watch.ElapsedMilliseconds}");
watch.Reset();
Queue<int> que = new Queue<int>(new int[1000]);
watch.Start();
for (int i = 0; i < 10000; i++)
{
for (int j = 0; j < 10000; j++)
{
que.Enqueue(0);
que.Dequeue();
}
}
watch.Stop();
Console.WriteLine($"큐 측정 시간: {watch.ElapsedMilliseconds}");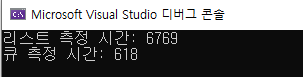
상기 코드는 각각 1000개의 원소를 가지는 리스트와 큐에서 원소 삽입과 맨 앞 원소 제거를 1억번 반복하는데 시간이 얼마나 걸리는지 측정하는 내용입니다. 큐에 비해서 리스트에서 약 10배이상의 시간이 걸린 것을 알 수 있습니다. 만약에 여기서 초기 원소의 갯수를 10배로 늘리면 어떻게 될까요?
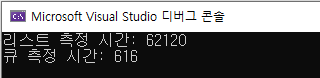
리스트는 거의 9배 정도 시간이 늘어났지만, 큐는 거의 차이가 없다는 것을 알 수 있습니다. 리스트에 관한 포스팅에서도 언급했지만 리스트에서 원소의 삭제는 그 뒤쪽에 있던 원소들의 인덱스 갱신을 유발합니다. 원소의 갯수가 많으면 많을수록 원소를 1개 삭제하는데 (낮은 인덱스의 원소일수록)많은 시간을 소요하게 되는 반면, 인덱스를 포함하지 않는 큐에서는 별 문제가 되지 않습니다. 한마디로 원소의 삽입과 제거를 자주 반복해야 하는 경우, 리스트보다 큐나 스택으로 구현하는 것이 좋다는 것입니다. 각종 알고리즘에서도 변수를 일시적으로 저장할 때 주로 큐나 스택을 사용하곤 합니다. 대표적으로 길찾기 문제에서 이동할 수 있는 다음 노드를 큐에 저장할 경우 BFS(Breadth-First Search), 스택에 저장할 경우 DFS(Depth-First Search)가 됩니다.
5. 큐와 스택의 capacity
이번 포스팅을 작성하면서 끝까지 해결하지 못한 궁금증이 있습니다. 바로 큐와 스택에서는 Capacity 속성 값을 제공하지 않는다는 점입니다. 사실 큐와 스택의 생성자를 보면 int 값을 매개변수로 넘겨서 초기 capacity 값을 미리 지정할 수도 있게 하였고, TriemExess()와 같이 capacity 값을 조정하는 함수도 제공하고 있습니다. 그런데 이 값을 속성으로 제공하여 확인할 수 있는 리스트와 달리, 큐와 스택은 capacity를 중간에 확인할 수 있는 방법이 없습니다. 구글링도 해보았지만 추측만 있을뿐 명확한 해답은 얻지 못했습니다. 해당 내용은 추후 알게되면 보강하도록 하겠습니다.
'C#' 카테고리의 다른 글
| [C#] 대리자(Delegate) (0) | 2023.02.09 |
|---|---|
| [C#] IComparable 인터페이스, Comparison<T> 대리자 (0) | 2023.01.31 |
| [C#] 딕셔너리(Dictionary) (0) | 2023.01.27 |
| [C#] 리스트(List) (0) | 2023.01.25 |
| [C#] 배열(Array) (0) | 2023.01.20 |



