
멈추지 않고 끈질기게
[DB][SQL] 데이터의 검색 본문
※ 해당 포스팅은 개인의 공부 정리용 글입니다. 틀린 내용이 있다면 추후 수정될 수 있습니다.
※ 해당 포스팅은 Mycrosoft SQL Server에서 사용하는 T-SQL 문법을 기반으로 하고 있으며, 예시는 SSMS(SQL Server Management Studio) 환경에서 작성하고 있습니다.
이번 포스팅에서는 SQL 문법에서 데이터 검색의 기초가 되는 SELECT, FROM, WHERE에 대해 알아보겠습니다.
1. SELECT와 FROM
SELECT와 FROM은 데이터 검색에 사용하는 가장 기초가 되는 키워드이며, 다음과 같이 사용합니다.
SELECT 속성명1, 속성명2, ...
FROM 테이블명임시로 만든 players 테이블을 기준으로 예시를 들어보겠습니다.

그림 1은 playerID, nickname, lv, curGold, class, guild의 6가지 속성을 가지는 테이블입니다. 위와 같이 테이블의 모든 속성을 확인하고 싶은 경우 SELECT 뒤에 *을 작성하면 됩니다. 해당 테이블에서 닉네임과 레벨만 확인하고 싶다면 다음과 같이 작성하면 됩니다.
SELECT nickname, lv
FROM players
또한 AS 키워드를 통해 속성명을 변경해서 출력할 수도 있습니다. 다음은 playerID를 PID로, lv를 Level로 출력하도록 변경하는 예시입니다. 참고로 -- 우측 내용은 주석입니다(C++, C#의 // 와 동일).
-- playerID -> PID, lv -< Level
SELECT playerID AS PID, lv AS Level
FROM players
players 테이블에서 playerID와 lv를 출력하고 있지만, 속성명은 PID와 Level로 변경된 것을 알 수 있습니다. 참고로 AS 키워드는 결과 테이블에 적용되는 것으로, 원본 테이블의 속성명이 변경되는 것은 아닙니다.
SELECT로 검색한 결과 테이블은 반드시 투플의 유일성을 보장하진 않습니다. 예를 들어 players 테이블에서 class 속성만을 추출한다면, Warrior 값이 중복으로 등장하게 됩니다. 중복 데이터를 제거하고 싶다면 SELECT 뒤에 DISTINCT 키워드를 붙이면 됩니다. 다음은 class 속성 검색 시 DISTINCT 키워드에 따른 차이를 비교하는 예시입니다.
-- 중복 허용
SELECT class
FROM players
-- 중복 제거
SELECT DISTINCT class
FROM players
결과 테이블을 보면 DISTINCT 키워드를 사용한 경우 중복이 제거되어 Warrior 클래스가 한번만 등장하는 것을 확인할 수 있습니다. 특이한 점은 DISTINCT를 사용한 결과 테이블은 데이터가 사전 순서대로 정렬되어 있는데, 이는 중복을 제거하기 위해 데이터를 정렬하기 때문입니다. 정렬에 관한 자세한 내용은 추후 포스팅에서 다루도록 하겠습니다.
2. WHERE
WHERE 키워드를 사용하여 데이터 검색에 추가적인 조건을 걸어줄 수 있습니다.
SELECT 속성명1, 속성명2, ...
FROM 테이블명
WHERE 조건식1 (AND/OR) 조건식 2 (AND/OR) ...
WHERE 뒤에 들어갈 조건식에는 비교 대상간의 도메인이 일치해야 한다는 제약 사항이 있습니다. 위의 players 테이블을 예로 들면, 문자열(VARCHAR) 타입인 nickname 속성을 상수값과 비교하면 에러가 발생합니다. 다음은 players 테이블에서 레벨이 30 이상인 투플만 검출하는 예시입니다.
-- 모든 속성 출력
-- 레벨이 30 이상인 유저의 데이터 출력
SELECT *
FROM players
WHERE lv >= 30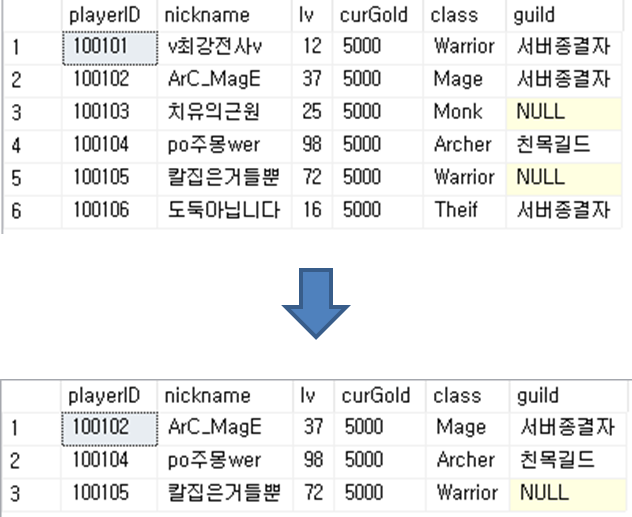
또한 AND, OR 키워드를 통해 조건식 여러개를 중첩해서 사용할 수 있습니다. 다음은 서버종결자 길드에 속한 레벨 30이상의 유저 데이터를 출력하는 예시입니다('서버종결자' 문자열 앞에 N을 붙인 것은 T-SQL 문법으로, 한글을 입력하기 위함입니다).
-- 모든 속성 출력
-- 서버종결자 길드 소속 레벨 30이상 유저
SELECT *
FROM players
WHERE guild = N'서버종결자' AND lv >= 30
물론 AND와 OR을 여러개 중첩할수도 있으며, 이 경우 연산 순서에 따라 결과가 달라질 수 있습니다. 이럴때는 괄호를 통해 연산 순서를 명확하게 해주는 것이 정확한 연산은 물론 가독성 측면에서도 좋습니다.
주의할 점은 NULL값은 아예 데이터가 없는 상태이므로, 일반적인 조건식을 적용할 수 없습니다. 해당 속성이 NULL값인지 아닌지 확인하려면 IS NULL 또는 IS NOT NULL 키워드를 사용해야 합니다. 다음은 길드에 속해있는 유저들의 데이터를 검색하는 예시입니다.
-- 모든 속성 출력
-- 길드에 속해 있는(NULL이 아닌) 유저 데이터 출력
SELECT *
FROM players
WHERE guild IS NOT NULL
3. ORDER BY
ORDER BY 키워드를 통해 검색 결과를 원하는 기준(속성)에 따라 정렬할 수 있습니다.
SELECT 속성명1, 속성명2, ...
FROM 테이블명
WHERE 조건식1 (AND/OR) 조건식 2 (AND/OR) ...
ORDER BY 속성1 (ASC/DESC), 속성2 (ASC/DESC), ...정렬 기준으로 여러개의 속성을 입력할 수도 있으며, 이 경우 먼저 입력한 쪽이 우선순위가 높습니다(속성1로 정렬 -> 속성1 값이 같은 행은 속성2에 따라 정렬 -> ...). 각 속성마다 ASC(오름차순), DESC(내림차순)을 붙여 정렬 방향을 설정할 수 있으며, 생략할 경우 디폴트 값은 ASC 입니다. 다음은 유저 데이터를 길드명 기준 내림차순, 레벨 기준 오름차순으로 정렬하도록 하는 쿼리와 결과입니다.
-- 길드명 기준 내림차순(1순위)
-- 레벨 기준 오름차순(2순위) 정렬
SELECT *
FROM players
ORDER BY guild DESC, lv ASC;
결과를 보면 친목길드 -> 서버종결자 -> NULL 순으로 정렬되었으며, 같은 서버종결자 길드 소속 유저들은 레벨 기준 오름차순으로 정렬된 모습을 확인할 수 있습니다.
다만 실제 데이터베이스의 경우 데이터 양이 굉장히 많기 때문에, 정렬을 생각없이 사용했다간 큰 비용이 발생할 수 있습니다. 이러한 정렬 비용 발생을 막으려면 인덱스(index)를 활용해야 합니다. 인덱스는 매우 중요한 내용이므로 추후 별도의 포스팅에서 다루도록 하겠습니다.
'DB' 카테고리의 다른 글
| [DB][SQL] 테이블, 속성의 추가/변경/삭제 (0) | 2023.05.05 |
|---|---|
| [DB][SQL] 그룹화와 집계 함수 (0) | 2023.05.03 |
| [DB] 관계 데이터 모델 (0) | 2023.04.22 |
| [DB] 데이터 모델링 (0) | 2023.04.17 |
| [DB] 데이터베이스 관리 시스템(DBMS) (0) | 2023.04.09 |



