
멈추지 않고 끈질기게
[컴퓨터 공학] 멀티 프로세스 vs 멀티 스레드 본문
※ 해당 포스팅은 개인의 공부 정리용 글입니다. 틀린 내용이 있다면 추후 수정될 수 있습니다.
이번 포스팅에서는 멀티 프로세스(multi process)와 멀티 스레드(multi thread)의 차이에 대해서 알아보겠습니다.
1. 프로세스(Process)와 스레드(Thread)
실행되기 전의 프로그램은 보조기억장치에 저장되어 있으며, 메모리에 적재하여 실행되는 순간 이를 프로세스라 합니다.
일반적으로 '실행중인 프로그램'이라고 부르는 것이 프로세스에 해당합니다. 이 때 프로세스가 메모리에서 차지하는 공간을 크게 코드 영역, 데이터 영역, 힙 영역, 스택 영역의 4가지로 구분합니다.
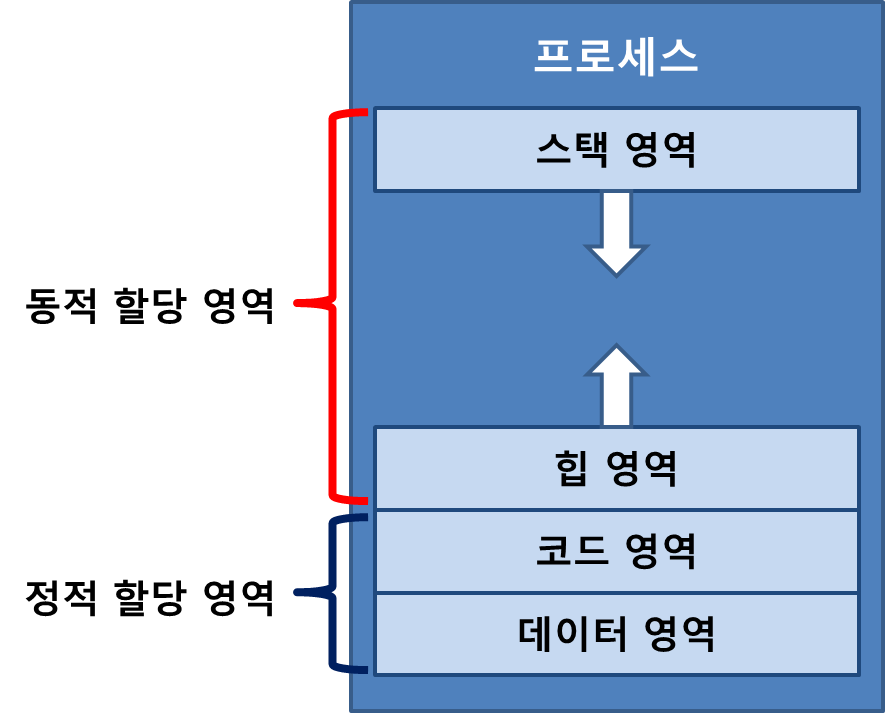
코드 영역(code segment)은 프로그램의 명령어가 저장되는 공간으로, 읽기 전용 공간입니다. 데이터 영역(data segment)은 프로그램이 실행되는 동안 유지될 데이터(ex.전역 변수)가 저장되는 공간입니다. 이 두 영역을 합쳐서 정적 할당 영역이라고 합니다(실행 중 크기 변화 X).
힙 영역(heap segment)은 실행중에 동적으로 할당할 수 있는 공간입니다. 대표적으로 코드상에서 new 키워드로 인스턴스를 생성하는 경우 힙 영역에 쓰이게 됩니다. 다만 동적으로 할당하는 만큼, 더이상 사용하지 않을 때 지워주지 않는다면 메모리 공간을 낭비하게 됩니다(메모리 누수). 따라서, C++과 같은 언어에서는 new 키워드로 생성한 만큼 추후 delete 키워드로 제거해야 합니다. C#과 같이 가비지컬렉터를 쓰는 언어에서는 별도로 지워주지 않아도 되지만, 가비지컬렉터의 호출 자체가 순간적인 성능 저하를 일으키기 때문에 이를 염두에 두어야 합니다. 스택 영역(stack segment)은 일시적인 데이터(ex.지역 변수)가 저장되는 공간입니다. 이 두 영역을 합쳐서 동적 할당 영역이라고 합니다(실행 중 동적으로 크기 변화).
여러개의 프로세스는 OS에 의해 CPU 자원을 분배받으며 번갈아 실행되는데, 실행중이던 프로세스를 멈추고 다른 프로세스를 실행하는 것을 문맥 교환(Context Switching)이라 합니다. 여기서 문맥(Context)이란 프로세스를 실행하기 위해 필요한 정보들을 말합니다. 각 프로세스마다 메모리의 커널 영역에 PCB(Process Control Block - 프로세스 제어 블록)를 가지고 있으며, 여기에는 PID(프로세스 아이디), 레지스터 값, 프로세스 상태 등의 정보, 즉 문맥이 저장됩니다. CPU가 PCB를 참조하며 문맥 교환을 통해 여러개의 프로세스를 빠르게 번갈아 실행하기 때문에 우리는 여러개의 프로세스를 동시에 실행할 수 있습니다. 단, 이 문맥 교환 때문에 발생하는 이슈도 있으며, 이는 밑에서 설명하겠습니다.
스레드는 프로세스를 구성하는 실행 단위로, 한 프로세스 안에 여러개 존재할 수 있습니다. 프로세스가 하나의 스레드만을 실행한다면 단일 스레드 프로세스, 여러개의 스레드를 실행한다면 멀티 스레드 프로세스라 합니다. 일반적으로 코드를 작성한 뒤 실행하면 단일 스레드로 실행되고, 별도로 스레드를 생성하려면 프로그래밍 언어마다 존재하는 스레드 생성 및 실행 방식을 따라야 합니다. 하기 예제는 C#에서 스레드를 생성, 실행하는 아주 간단한 코드입니다.
public static void Hello()
{
//스레드 일시정지(ms 단위)
Thread.Sleep(1000);
Console.Write("Hello ");
}
static void World()
{
Thread.Sleep(2000);
Console.WriteLine("World");
}
static void Main(string[] args)
{
//스레드 선언 및 초기화
Thread t1 = new Thread(Hello);
Thread t2 = new Thread(World);
//스레드 시작
t1.Start();
t2.Start();
//t1, t2 스레드가 종료될 때까지 대기
t1.Join();
t2.Join();
}C#에서 스레드를 사용하려면 System.Threading 네임스페이스를 참조해야 합니다. 스레드에서 독립적으로 수행할 작업을 함수로 작성한 뒤, Thread 클래스의 생성자로 넘겨주면서 스레드를 초기화했습니다. 각 스레드는 Start()함수로 실행할 수 있으며, Join() 함수를 통해 메인 함수가 두 스레드의 작업이 끝날 때까지 대기하도록 했습니다. Thread.Sleep()은 해당 코드를 실행중인 스레드를 매개변수 시간만큼 일시정지 시키며, 단위는 ms 입니다. 실행하면 약 1초 뒤에 Hello, 다시 1초 뒤에(합 2초) World 문자열을 출력한 뒤 종료됩니다. 이렇게 별도의 스레드로 실행한 작업은 메인 스레드와 병행하여 실행되기 때문에, 스레드를 활용하면 하나의 프로그램(프로세스)에서 한번에 여러가지 작업을 동시에 수행할 수 있습니다.
2. 멀티 프로세스(Multi Process)와 멀티 스레드(Multi Thread)
여러개의 프로세스를 동시에 실행하는 것을 멀티프로세스라 하고, 한 프로세스 안에서 여러개의 스레드를 동시에 실행하는 것을 멀티스레드라 합니다. 둘 다 여러개의 작업을 동시에 수행할 수 있다는 특징이 있지만, 둘 사이에는 메모리 공간의 차지 여부에서 차이가 있습니다.

메모리에 할당된 프로세스의 영역에는 위에서 설명한 4가지 영역과 프로그램 카운터, 레지스터 등이 할당되어 있습니다. 멀티 프로세스는 여러개의 독립된 프로세스를 동시에 실행하며, 프로세스의 수만큼 메모리 공간을 배로 사용하기 때문에 메모리를 많이 차지하게 됩니다.

반면, 멀티스레드는 하나의 프로세스에서 여러개의 스레드를 사용하는 형태입니다. 각 스레드는 프로세스 안에서 스택 영역과 프로그램 카운터, 레지스터 등은 별도로 가지지만, 코드 영역, 데이터 영역, 힙 영역은 프로세스 전체의 것을 공유하기 때문에 멀티 프로세스 방식에 비해서 메모리를 절약할 수 있습니다. 또한 자원을 공유하기 때문에 스레드 간 협력과 통신이 용이합니다.
다만 자원의 공유는 반드시 장점만이 되지는 않습니다. 어떤 자원에 문제가 발생한다면, 해당 자원을 이용하는 모든 스레드들에 오류가 발생하게 됩니다. 특히 같은 자원에 접근하는 스레드들이 동기화 되어있지 않다면 이슈를 발생시킬 확률이 매우 높습니다.
엑셀로 비유하자면 멀티 프로세스는 엑셀 파일을 여러개 만들어 사용하는 것이고, 멀티 스레드는 하나의 엑셀 파일에서 여러개의 시트를 사용하는 것과 비슷합니다. 비슷한 동작을 하거나 관련있는 데이터를 저장할 것이라면 후자가 용이할 것입니다. 또한 한 엑셀 파일 안의 다른 시트끼리는 쉽게 참조할 수 있습니다. 다른 엑셀 파일에 저장된 데이터를 가져오려면 좀 더 복잡한 외부 데이터에 접근하는 양식을 사용하거나 데이터를 통째로 복사해야 합니다. 물론 한 파일 안에서 다른 시트를 참조하는 경우 대상 시트의 데이터에 오류가 발생하면 이를 참조한 다른 모든 시트의 데이터도 오류가 발생한다는 점은 주의해야 할 것입니다.
3. 멀티 스레드에서 공유 자원의 사용(동기화 이슈)
멀티 스레드 프로그래밍 시, 복수의 스레드에서 공용 자원에 접근할 경우 반드시 스레드들이 동기화되어야 합니다.
public static int count = 0;
public static void Plus()
{
for (int i = 0; i < 10000; i++)
count++;
}
static void Minus()
{
for (int i = 0; i < 10000; i++)
count--;
}
static void Main(string[] args)
{
Thread t1 = new Thread(Plus);
Thread t2 = new Thread(Minus);
t1.Start();
t2.Start();
//t1, t2 스레드가 종료될 때까지 대기
t1.Join();
t2.Join();
Console.WriteLine(count);
}상기 코드의 내용은 단순합니다. 전역 변수 count를 0으로 초기화하였고, count를 1씩 10,000번 증가시키는 Plus() 함수와 1씩 10,000번 감소시키는 Minus() 함수를 선언하였습니다. 메인 함수에서 Plus()와 Minus()를 실행하는 스레드 t1, t2를 선언하였고, 연달아 실행 후 두 스레드가 모두 종료된 후에 count 값을 출력합니다.
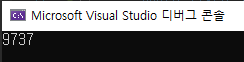


단순하게 생각해서 ++연산을 만번, --연산을 만번 실행했으니 0이 나올거 같지만, 실제로는 전혀 예상하지 않은 값이 나오며 심지어 실행할 때마다 다른 값이 나옵니다. 이는 두 스레드가 동기화되어 있지 않기 때문에 발생하는 현상입니다.
count++나 count--는 코드 상에서는 단 한줄로 끝나는 간단한 코드이지만, 실제로 CPU가 처리할 때는 여러개의 명렁어를 거쳐 처리됩니다. 따라서 동기화 되지 않은 스레드들이 같은 자원에 접근할 경우, 다음과 같은 문제가 발생할 수 있습니다.

r1, r2는 예시를 들기 위해 임의의 레지스터 주소에 이름을 붙인 것입니다. count++는 r1에 기존의 count 값을 저장한 후, 해당 레지스터의 값을 1 올리고 count에 r1의 값을 할당합니다. count--는 r2에 기존의 count 값을 저장한 후, 해당 레지스터의 값을 1 내리고 count에 r2의 값을 할당합니다. 이렇듯 한줄의 코드라 할지라도 실제 명령어 상으로는 여러 단계로 나뉘기 때문에, 비동기화된 스레드들을 각각 실행할 경우 데이터의 일관성을 해치는 문맥 교환이 일어날 수 있습니다. 상기 도식은 count++의 명령어 중 r1 값을 증가시키는 명령어까지 실행되고 count에 쓰기 전에 문맥 교환이 일어난 경우를 나타낸 것입니다. 아직 count값이 갱신되기 전에 count-- 의 모든 명령어가 실행되면서 count 값이 -1이 되었지만, 그 이후에 r1의 값을 count에 쓰면서 1로 덮어버립니다. 즉, count++ 와 count--가 각각 한번씩 실행되었는데 결과적으로 count가 1 증가한 상황이 되었습니다. 또한 문맥 교환이 어느 지점에서 일어날지는 실행할 때마다 바뀔 수 있기 때문에, 상기 코드의 실행 결과가 매번 달라지는 현상이 나타나는 것입니다.
스레드간의 동기화는 매우 중요한 문제이며, 그 해결책 또한 여러가지가 있기 때문에 해당 내용은 다른 포스팅에서 더 자세하게 다루도록 하겠습니다.
'컴퓨터공학' 카테고리의 다른 글
| [컴퓨터공학] 교착 상태(Dead Lock) (0) | 2023.03.04 |
|---|---|
| [컴퓨터공학] 스레드의 동기화 (0) | 2023.03.03 |
| [컴퓨터 공학] 가상 메모리(virtual memory) (0) | 2023.02.10 |
| [컴퓨터 공학] 0.11f * 3 == 0.33f ? (0) | 2023.02.03 |
| [컴퓨터 공학] 캐시 메모리(Cache Memory) (0) | 2023.01.30 |



